My first story on the Google Cloud Platform cost optimization was about the hidden secrets of Looker Studio (formerly Google Data Studio). Let me tell you another story on how to find the source of soaring costs. Some new cool features for cost optimization are now available on GCP so let’s start.
The support team lead reached out to me asking if we can get the content of comments from Intercom. Our users rate closed conversations with the support team from time to time and leave comments on the rating. The problem was that some users continued the conversation in these comments and the support team had to manually check it daily.
This led to a delay in answers to users’ questions, and we did not want that. So the idea was to automatically alert the support team when we get a new comment as soon as possible. We checked that Intercom had the corresponding data point called remark in their data model. So it was possible to get this data through API.
Intercom to BigQuery pipeline with Airbyte
At the same time, I was playing with Airbyte as an EL tool in the ELT paradigm. Airbyte can connect data sources with destinations in a simple user interface. It already had the Intercom as a data source, so I set up the connection between Intercom and BigQuery.
The source setup required an Intercom API key only and was simple:

The destination setup was more interesting because I used Google Cloud Storage data staging. This required HMAC key setup for the GCP service account as an intermediary step. Also, I chose to use batch transformation query run time.

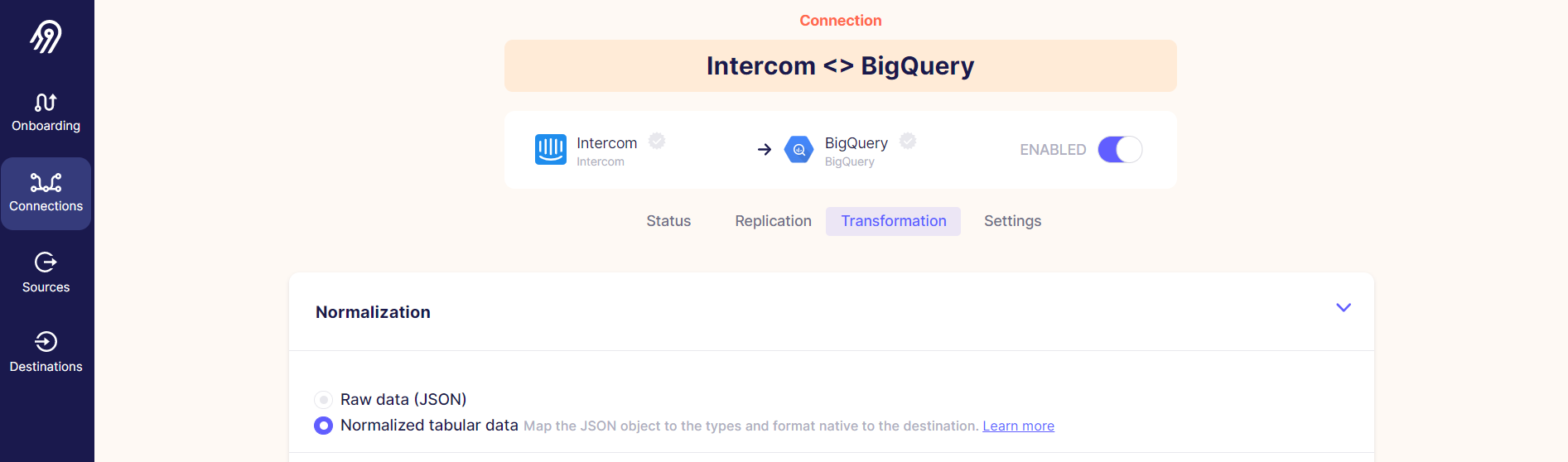
I connected the source to the destination and set the hourly replication frequency. The final option was data normalization so I decided to experiment with normalized data. Airtbyte uses dbt under the hood for data transformations, so I was pretty sure that it will incur some costs on BQ. The easiest way to estimate these costs was to run the pipeline several times to see the results.

Cost analysis with GCP Log Analytics
There is a Log Analytics tool in GCP, that lets you query your project logs using BigQuery. So if you are familiar with BigQuery SQL syntax, you can apply it here with no need to learn an additional logs query language. Log Analytics shows the data types for each column, so when you get JSON column type, use BigQuery JSON functions. The query that I used in my research was:
SELECT
SUM(CAST(JSON_VALUE(proto_payload.audit_log.service_data.jobGetQueryResultsResponse.job.jobStatistics, '$.totalBilledBytes') AS INT64))/1024/1024 AS total_billed_mb
FROM
`logs__Default_US._AllLogs`
WHERE
timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)
AND resource.type = 'bigquery_resource'
AND proto_payload.audit_log.authentication_info.principal_email = 'SERVICE_ACCOUNT_EMAIL'
SERVICE_ACCOUNT_EMAIL was the service account I used in the BigQuery destination setup in Airbyte. This query returned 800MB for each hourly data transformation which was far above my expectations regarding the total data size of 50MB. So I switched the normalization option in Airbyte to raw JSON data and got 30MB which is 26 times lower.
Working with JSON in BigQuery
It seems that raw JSON is not the best data type to store in BigQuery. But it is always about data storage and data consumption tradeoff in the on-demand BigQuery pricing model. So using the JSON functions, I got all the rating comments with this query:
SELECT
url,
rating_value,
remark
FROM (
SELECT
CONCAT('https://app.intercom.com/a/apps/INTECOM_APP_ID/inbox/inbox/all/conversations/', JSON_VALUE(_airbyte_data, '$.id')) AS url,
JSON_QUERY(_airbyte_data, "$.conversation_rating.created_at") AS remark_time,
JSON_QUERY(_airbyte_data, "$.conversation_rating.rating") AS rating_value,
JSON_QUERY(_airbyte_data, "$.conversation_rating.remark") AS remark,
FROM
`PROJECT_ID.DATASET_ID._airbyte_raw_intercom_conversations`
WHERE
DATE(_airbyte_emitted_at) >= CURRENT_DATE() - 1)
WHERE
remark IS NOT NULL
AND (UNIX_SECONDS(CURRENT_TIMESTAMP()) - CAST(remark_time AS INT64)) / 60 / 60 >= 1
GROUP BY
1,
2,
3
INTECOM_APP_ID, PROJECT_ID, and DATASET_ID are the placeholders here and must be replaced with existing values. Airbyte partitions the table by _airbyte_emitted_at, so I get the last two days of data and narrow it to the last hour. This reduced the cost of the entire pipeline even more. The query returns the data on the rating, the comment, and the link to the conversation in Intercom.
I used this query in the Python cloud function triggered hourly by Cloud Scheduler. Here is the cloud function code:
import functions_framework
import os
import telegram
from google.cloud import bigquery as bq
bq_query_remarks = (
"""
SELECT
url,
rating_value,
remark
FROM (
SELECT
CONCAT('https://app.intercom.com/a/apps/INTERCOM_APP_ID/inbox/inbox/all/conversations/', JSON_VALUE(_airbyte_data, '$.id')) AS url,
JSON_QUERY(_airbyte_data, "$.conversation_rating.created_at") AS remark_time,
JSON_QUERY(_airbyte_data, "$.conversation_rating.rating") AS rating_value,
JSON_QUERY(_airbyte_data, "$.conversation_rating.remark") AS remark,
FROM
`PROJECT_ID.DATASET_ID._airbyte_raw_intercom_conversations`
WHERE
DATE(_airbyte_emitted_at) >= CURRENT_DATE() - 1
)
WHERE
remark IS NOT NULL
AND (UNIX_SECONDS(CURRENT_TIMESTAMP()) - CAST(remark_time AS INT64)) / 60 / 60 >= 1
GROUP BY
1,
2,
3
"""
)
def send_tg_message(tg_text, tg_chat_id = os.environ['TELEGRAM_ERROR_CHAT_ID']):
bot = telegram.Bot(token = os.environ['TELEGRAM_TOKEN'])
bot.sendMessage(chat_id = tg_chat_id, text = str(tg_text))
def main(request):
try:
bq_client = bq.Client()
bq_job_config = bq.QueryJobConfig()
bq_job_config.use_query_cache = False
bq_job_config.use_legacy_sql = False
query_job = bq_client.query(bq_query_remarks, job_config = bq_job_config)
rows_df = query_job.result()
message_text = ''
for row in rows_df:
message_text += '\n{url}\nRating: {rating}\nRemark:{remark}\n'.format(url = row["url"], rating = row["rating_value"], remark = row["remark"])
if(len(message_text) > 0):
send_tg_message(tg_text = '#intercom_remarks\n' + message_text + '\n@SOMEONE_WHO_NEEDS_TO_KNOW', tg_chat_id = os.environ['TELEGRAM_MESSAGE_CHAT_ID'])
return 'ok'
except Exception as e:
send_tg_message(tg_text = 'Intercom remark to TG\n\n' + e)
return 'error'
The requirements.txt file is like this:
functions-framework==3.*
python-telegram-bot
google-cloud-bigquery
TELEGRAM_ERROR_CHAT_ID, TELEGRAM_MESSAGE_CHAT_ID, and TELEGRAM_TOKEN are runtime environment variables here. After the invocation, the function pulls the data from BigQuery and sends the message to Telegram chat notifying SOMEONE_WHO_NEEDS_TO_KNOW. This way all the data processing stays inside the GCP and inside the GCP free tier.
A note on Airbyte cost optimization by Martin Bach from restack.io
I think another way to cost optimize your cloud costs in case you self host Airbyte is actually to make use of Airbyte’s architecture. So for every connector Airbyte spins up multiple pods, for which you can set resource request and limits on your Kubernetes deployment.
If you run it manually, you can ensure observability and monitoring with Prometheus and Grafana and set resource limits accordingly to the average consumption of the spinned up pods per connector, but also the other pods for workloads like temporal, web, Postgres etc. You also can enable horizontal pod auto scaling and auto scaling of the cluster to ensure it runs reliably even if you would have a peak in data.
Final thoughts
I’ll be building more pipelines with Airbyte in the future. Custom data transformatioтs is the most interesting feature that I did not try yet. I’ll also use different data sources and maybe one day even get rid of all my R scripts that are transferring data from everywhere to BigQuery. Let me know if you have a more elegant and cost effective solution for this case.