Let’s start with a simple question: for each tool in my product what fraction of daily active users per day visits the tool? Maybe not so simple so let me add some assumptions to simplify the solution.
-
Daily active user is the one who visits at least one tool per day.
-
You have a lot of tools in the product and you add some new tools from time to time.
-
You have a my_project.my_dataset.my_table table in BigQuery with these fields:
- date - the date when the user visited the page
- userId - the ID of signed in user for you to be able to count all the users who visited the tool
- pagePath - the URL of the web page that uniquely identifies each tool in your product
The overview of the query
You query should reflect the following algorithm:
Step 1. For each date and user check what tools the user visited.
Step 2. For each date and each tool count the number of users and divide it by the total number of users per day for the users who visited at least one tool per day.
As a pseudo-query it would look like this:
SELECT
date,
COUNT(DISTINCT userId) AS users,
[SUM({tool_name}) / COUNT(DISTINCT userId) AS {tool_name}]
FROM (
SELECT
date,
userId,
[MAX(CAST(REGEXP_CONTAINS( pagePath, r'{tool_regexp}') AS INT64)) AS {tool_name}]
FROM
`{your_table}`
WHERE
{additional_internal_conditions}
GROUP BY
date,
userId
ORDER BY
userId,
date)
WHERE
([active_user_conditions])
GROUP BY
date
ORDER BY
date
I use {…} notation here to highlight some variables that you need to fill in to get the final query. Also I use […] notation to highlight some expressions with variable length. Each time you add a new tool to your product you’ll have to update your query. For 2 or even 5 tools this process is easy and your query is short enough to edit it manually.
But let’s grow your product to tens of even hundreds of tools and you immediately get an SQL behemoth in your text editor. It becomes hard to maintain and prone to errors. A missed comma here or there and here come troubles. Especially if you are on vacation and your colleague wants to update the query without your knowledge.
Decomposing the query
To even more simplify the whole idea here is a pseudo-pseudo-query :)
prefix_counts
counts
prefix_indicators
indicators
condition_indicators
condition_counts
suffix_counts
This prefix_ / suffix_ notation is related to SQL statements block. So prefix_counts is equals to
SELECT
date,
COUNT(DISTINCT userId) AS users,
part of the query here.
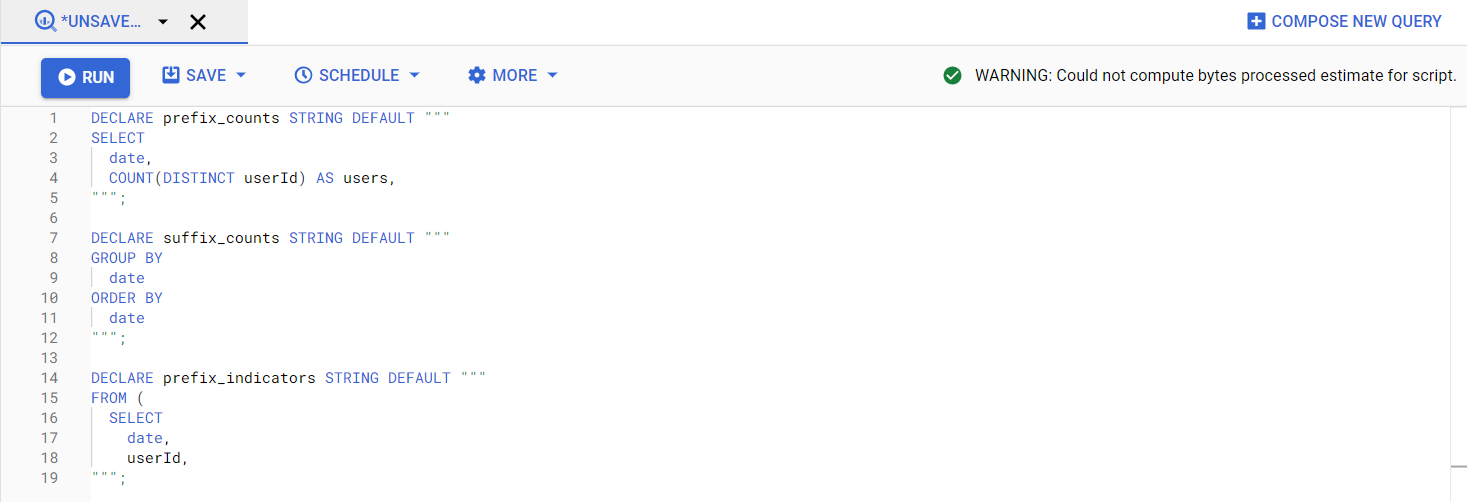
There is a really cool tool in BigQuery called scripting. It lets you declare some variables, set values for these variables and use these variables later in SQL statements. Let’s start with the first variable to set prefix_counts:
DECLARE prefix_counts STRING DEFAULT """
SELECT
date,
COUNT(DISTINCT userId) AS users,
""";
Note that each scripting statement must be followed by a semicolon. Now you have a string variable called prefix_counts with default value set to the first part of the SQL statement. Let’s continue with other fixed variables:
DECLARE suffix_counts STRING DEFAULT """
GROUP BY
date
ORDER BY
date
""";
DECLARE prefix_indicators STRING DEFAULT """
FROM (
SELECT
date,
userId,
""";
DECLARE condition_indicators STRING DEFAULT """
FROM
`my_project.my_dataset.my_table`
WHERE
userId IS NOT NULL
AND pagePath IS NOT NULL
GROUP BY
date,
userId)
""";
DECLARE indicators, counts, condition_counts STRING;
You declared indicators, counts, condition_counts string variables here without setting the default value. We will do this later. It is a necessary step because all DECLARE statements must be placed at the beginning of the script.
Note that if your my_project.my_dataset.my_table table is partitioned by date then you should add some filtering conditions based on dates to WHERE statement in condition_indicators query part. This will reduce the costs of your queries to queried partitions only.
Building SQL query from the values stored in separate table
The easy part is done. No we have to make a step back to […] notation. You will have to build the SQL statement with variable length based on your knowledge of all the tools in your product. Basically it means that you need some way to construct strings from a predefined set of values which are a kind of predefined specification for URLs of all the tools.
To store this specification I use a table with regexp and name string fields. Using the value from regexp field in REGEXP_CONTAINS() BigQuery function I can test if the user visited the tool and save an indicator (1 if visited, 0 if not) for each user named with value from name field. Go and run this query in BigQuery to get the idea:
CREATE OR REPLACE TEMP TABLE temp_table AS (
SELECT
*
FROM ((
SELECT
'^/projects_list/' AS regexp,
'projects_list' AS name)
UNION ALL (
SELECT
'^/domain/seo/' AS regexp,
'domain_seo_overview' AS name)) );
SELECT
*
FROM
temp_table;
This query creates a temporary table called temp_table with the same structure as I use to store the specification. Just to be clear, I use a temporary table as an example here and below. My permanent table with the specification has 80+ rows.
Using CONCAT() BigQuery function you can construct a set of strings that will tests pagePath using regexp and return 0 or 1 in the final query:
SELECT
CONCAT("MAX(CAST(REGEXP_CONTAINS( page.pagePath, r'", regexp, "') AS INT64)) AS ", name) AS rez
FROM
temp_table
This gives you a number of rows that you can combine into ARRAY like this:
SELECT
ARRAY(
SELECT
CONCAT("MAX(CAST(REGEXP_CONTAINS( pagePath, r'", regexp, "') AS INT64)) AS ", name) AS rez
FROM
temp_table)
Now you have a single array that you can collapse to a single string using comma and new line delimiter to improve the readability of final query:
SELECT
ARRAY_TO_STRING((
SELECT
ARRAY(
SELECT
CONCAT("MAX(CAST(REGEXP_CONTAINS( pagePath, r'", regexp, "') AS INT64)) AS ", name) AS rez
FROM
temp_table)), ',\n')
So now you have indicators part of or pseudo-pseudo-query. Using the same approach you can build counts and condition_counts by declaring these variables and setting the values:
SET indicators = (SELECT
ARRAY_TO_STRING((
SELECT
ARRAY(
SELECT
CONCAT("MAX(CAST(REGEXP_CONTAINS( pagePath, r'", regexp, "') AS INT64)) AS ", name) AS rez
FROM
temp_table)), ',\n'));
SET counts = (SELECT
ARRAY_TO_STRING((
SELECT
ARRAY(
SELECT
CONCAT("SUM(", name, ") / COUNT(DISTINCT userId) AS ", name) AS rez
FROM
temp_table)), ',\n'));
SET condition_counts = (CONCAT("WHERE ( ", ARRAY_TO_STRING((
SELECT
ARRAY(
SELECT
name
FROM
temp_table)), '+'), ") > 0"));
Note, that you must wrap up the query with additional parentheses in SET statements. If you miss this BigQuery will kindly remind you with the error message.
One last step is to combine all our strings into one single SQL statement like this:
SELECT
CONCAT(
prefix_counts,
counts,
prefix_indicators,
indicators,
condition_indicators,
condition_counts,
suffix_counts
)
Final script and the resulting query
The final script with temporary table will look like this:
DECLARE prefix_counts STRING DEFAULT """
SELECT
date,
COUNT(DISTINCT userId) AS users,
""";
DECLARE suffix_counts STRING DEFAULT """
GROUP BY
date
ORDER BY
date
""";
DECLARE prefix_indicators STRING DEFAULT """
FROM (
SELECT
date,
userId,
""";
DECLARE condition_indicators STRING DEFAULT """
FROM
`my_project_my_dataset_my_table`
WHERE
userId IS NOT NULL
AND pagePath IS NOT NULL
GROUP BY
date,
userId)
""";
DECLARE indicators, counts, condition_counts STRING;
CREATE OR REPLACE TEMP TABLE temp_table AS (
SELECT
*
FROM ((
SELECT
'^/projects_list/' AS regexp,
'projects_list' AS name)
UNION ALL (
SELECT
'^/domain/seo/' AS regexp,
'domain_seo_overview' AS name)) );
SET indicators = (SELECT
ARRAY_TO_STRING((
SELECT
ARRAY(
SELECT
CONCAT("MAX(CAST(REGEXP_CONTAINS( pagePath, r'", regexp, "') AS INT64)) AS ", name) AS rez
FROM
temp_table)), ',\n'));
SET counts = (SELECT
ARRAY_TO_STRING((
SELECT
ARRAY(
SELECT
CONCAT("SUM(", name, ") / COUNT(DISTINCT userId) AS ", name) AS rez
FROM
temp_table)), ',\n'));
SET condition_counts = (CONCAT("WHERE ( ", ARRAY_TO_STRING((
SELECT
ARRAY(
SELECT
name
FROM
temp_table)), '+'), ") > 0"));
SELECT
CONCAT(
prefix_counts,
counts,
prefix_indicators,
indicators,
condition_indicators,
condition_counts,
suffix_counts
)
BigQuery will perform multiple steps while executing this query and the final step will show you the desired result:
SELECT
date,
COUNT(DISTINCT userId) AS users,
SUM(domain_seo_overview) / COUNT(DISTINCT userId) AS domain_seo_overview,
SUM(projects_list) / COUNT(DISTINCT userId) AS projects_list
FROM (
SELECT
date,
userId,
MAX(CAST(REGEXP_CONTAINS( pagePath, r'^/domain/seo/') AS INT64)) AS domain_seo_overview,
MAX(CAST(REGEXP_CONTAINS( pagePath, r'^/projects_list/') AS INT64)) AS projects_list
FROM
`my_project_my_dataset_my_table`
WHERE
userId IS NOT NULL
AND pagePath IS NOT NULL
GROUP BY
date,
userId)
WHERE ( domain_seo_overview+projects_list) > 0
GROUP BY
date
ORDER BY
date
Executing the query from the same script
I’m pretty sure you want to know how to run this query in the same script. Wrap up the final SELECT statement into EXECUTE IMMEDIATE() like this:
EXECUTE IMMEDIATE(
SELECT
CONCAT(
prefix_counts,
counts,
prefix_indicators,
indicators,
condition_indicators,
condition_counts,
suffix_final
)
)
Or you can declare the variable, set the result of this select statement to the variable and use this variable in EXECUTE IMMEDIATE() statement.
What you can do with the final query
Now you know how to construct complex queries using SQL. I use a query like this as a scheduled query that uploads new data to the table on a daily basis. Every time we add a new tool to our product I add a row in a table with a specification and a column to the table with the results of the query. This can be done using some SQL statements too but that would be a topic for another article.
Share your thoughts on this approach. Does it work for you?