I’ve been using Google BigQuery since its’ public release and I like where it has been going through all these years. The team behind the product is doing an amazing job and I do not remember any public feature with no apparent use case.
One of the most noticeable BigQuery evolution branches for me is from simple storage and query engine to internal scheduled queries mechanism and a non-linear interconnected query logic for data manipulation later on. You definitely can try to build a complicated query logic with BigQuery scheduled queries but at some point, it becomes a fragile construction with a lot of edge cases to solve.
Dataform features
And that is where Dataform comes into play. It is a told for data transformations inside the database. In terms of the extract-load-transform paradigm, it is responsible for the transform step. The ingested data is transformed using internal database capabilities with the cool features on top of that like:
- Data transformation description in SQL, JS, and JSON code
- Git repository connection for code storage, so you can use all the version control system features
- Entities creation and documentation in the code
- The data quality tests using entities called assertions
- Common code snippets wrapped up into reusable functions and constants
- The project schedule and run using built-in flexible mechanisms
- Custom alerts on success or failure
- External JS dependencies management
- Visual representation of all the connections of entities in the project
As a result, Dataform spills out all the code as a pure SQL and runs it inside the database. And the coolest part is that Dataform is now a part of Google BigQuery in the Google Cloud Platform. Please note, however, that Dataform is in the preview stage so some features are not available yet. Anyway, you can try it with your project in GCP to feel the taste.
Now let’s take a break for a minute and look around. Some other tools have the same features. The first one to mention is dbt. It is external to GCP but it is also not native to GCP. So the latter might be a good argument to use Dataform if you don’t want to go out of GCP and BigQuery.
Dataform setup
So let’s get back to Dataform. You can use it with non-GCP databases but let’s stay inside the GCP in this article. Now go to Dataform and create a new repository. Give it a name and select a region. These can not be changed later.

After the repository is created Dataform will remind you to grant access for the GCP service account that it uses. Make sure you do that before running any code in Dataform because you’ll get access denial errors otherwise.

You should get an empty repository like this:

The next important step is to connect your remote git repository to get all the power of the version control system. All the code of your data transformations will be stored there. Later on, you can build any branching logic you wish on top of this repository. You’ll have to create a secret key in your git provider and store it in GCP Secret Manager.

Now you can create a development workspace which will be translated into a separate branch into git. The development workspace will be the place where you work with the code.

It is empty by default and you can initialize it with default project configuration files. I was using Dataform before the merge with GCP, so I already have a Gitlab project with all the code. I pulled the data from the connected repository and got the development workspace up to date. The project file structure remains the same before and after the merge. Please check the migration guide before you do the same because you need to tweak the existing code for it to work as expected.
Create a data pipeline as a code
The project is a list of files that you can edit right into the interface. You can also create and delete files from here. Each file contains the instructions on what to do with your BigQuery data or with your Dataform project.

Let’s take a look at the example of such a file.
config {
type: "incremental",
description: "The sign-up dates of the users",
columns:{
user_id: "ID of the user",
sign_up_date: "The date when the user signed up"
},
bigquery:{
partitionBy: "sign_up_date",
labels: {
"stage": "beta"
}
},
assertions: {
uniqueKey: ["user_id"]
},
tags: ["daily"]
}
SELECT
CAST(user_id AS STRING) AS user_id,
DATE(registration_date) AS sign_up_date
FROM
${ref('users')}
WHERE
TRUE
${ when(incremental(), `AND CAST(user_id AS STRING) > (SELECT MAX(user_id) FROM ${self()})`) }
As you can see, it is a blend of SQL and JS called SQLX. The file starts with the config part that defines the actions that would be performed with the data and a description of the results of these actions.
For instance, I create the incremental table here with the description for the table and all columns. This table is partitioned by the sign_up_date column, labeled with stage:beta label, and tagged with daily tag. This code will create the table if it does not exist in my dataset in BQ or insert new values into the existing table. Also, the uniqueness of the values in the user_id column would be checked.
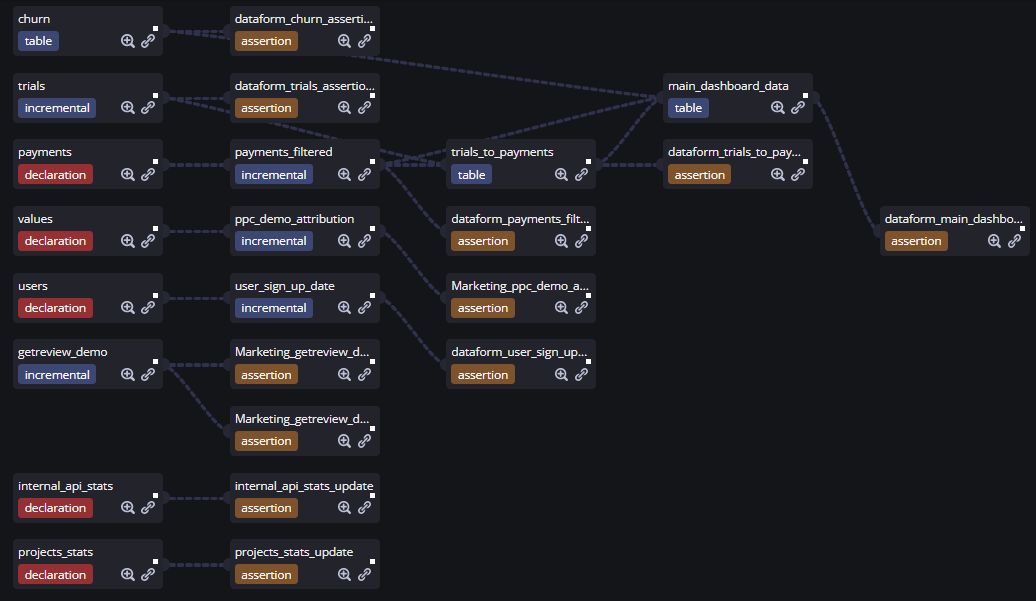
You can use ${ref()} command to reference other tables defined in your project or ${self()} command to reference current table. This way you can build complex sequences of actions with numerous dependencies. When Dataform will execute the project it will understand all of that and reduce BQ resource consumption by optimizing the data flow. Here is the visual representation of the dependencies tree in the pre-merge version of Dataform:

Project execution
The code above is compiled by Dataform into two separate pure SQL queries. One for the table creation or update:
SELECT
CAST(user_id AS STRING) AS user_id,
DATE(registration_date) AS sign_up_date
FROM
`project_id.dataset_id.users`
WHERE
TRUE
AND CAST(user_id AS STRING) > (SELECT MAX(user_id) FROM `project_id.dataset_id.user_sign_up_date`)
And one for table assertion:
SELECT
*
FROM (
SELECT
user_id,
COUNT(1) AS index_row_count
FROM `project_id.dataset_id.user_sign_up_date`
GROUP BY user_id
) AS data
WHERE index_row_count > 1
Dataform shows you all the compiled queries so you can check if they are correct. You can try to run the query in BQ directly:

Or you can start the execution of the query or a bunch of queries from Dataform:

The execution panel gives you the advanced options that are useful for mass data updates:

After the start of the execution you can go to the workflow executions log to check if everything worked as expected:

In case of any issues with the query, the execution will fail. You can view the details of the execution and fix the issue:

As a final step you can commit all the changes and push them to git, or revert the changes:

You can pull the changes from the main git branch here as well. Note that all the files in the project are editable. But it is always better to read the docs before you mess something up.
Missing pieces
Dataforms is currently on its way to full merge with GCP so a number of features are missing. For me, the most noticeable are:
- (Done) No built-in scheduler to trigger the project execution without external tools. You can run the project manually or use GCP scheduling tools.
- No auto updates of the Dataform core module. It would be great to get updates on the fly.
- No bright big button to execute all the actions in the current file without the need to wade through the dropdowns and menu items.
- (Done) Description can only be set at the table level and not at the column level.
I hope to see them soon in GCP.
Final thoughts
Dataform is a missing puzzle in BigQuery data pipelines and it is nice to see it on board finally. Oh, and did I mention that it comes for free? Just keep controlling BigQeury resources consumption and that’s it. For instance, check for unnecessary data assertions that do not provide any additional data quality but still consume resources.
Of course, not every data project needs Dataform or its alternatives. You don’t need all of that to run a single query once per month. But data QA, pipeline lineage control, and traceability are becoming more important with the growth of the project. A more complex data pipeline development process will speed you up in the end. So give it a go.
Here are some links to official documentation that will help you to get started with Dataform: